La investigación del Dr. Sánchez se centra en la Quimiogenómica Computacional, un área de investigación multidisciplinaria que busca identificar, mediante el uso de herramientas computacionales, las interacciones que pueden existir entre moléculas pequeñas y macromoléculas biológicas. Está área de investigación abarca desde el desarrollo y validación de nuevas metodologías computacionales, hasta el uso de dichas herramientas en la identificación de nuevos compuestos bioactivos. Las líneas de investigación principales del Dr. Sánchez son:
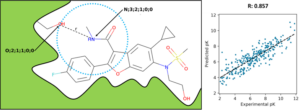
Desarrollo de modelos de aprendizaje automático para la predicción de la afinidad de compuestos químicos a proteínas.
Predecir la afinidad de una molécula pequeña a una determinada proteína es un problema central en la identificación de nuevos compuestos bioactivos, pues esto permitiría priorizar los ensayos experimentales a realizar, resultando en una disminución tanto en tiempos como en costos de las investigaciones. Un método computacional ampliamente utilizado para tal fin es el acoplamiento molecular, el cual ha demostrado ser capaz de identificar nuevas moléculas con actividad biológica, pero cuyas predicciones de afinidad distan de los valores experimentales obtenidos. Para abordar este problema, en nuestro grupo de investigación desarrollamos modelos de aprendizaje automático que nos permitan estimar dicha afinidad con una mayor exactitud.
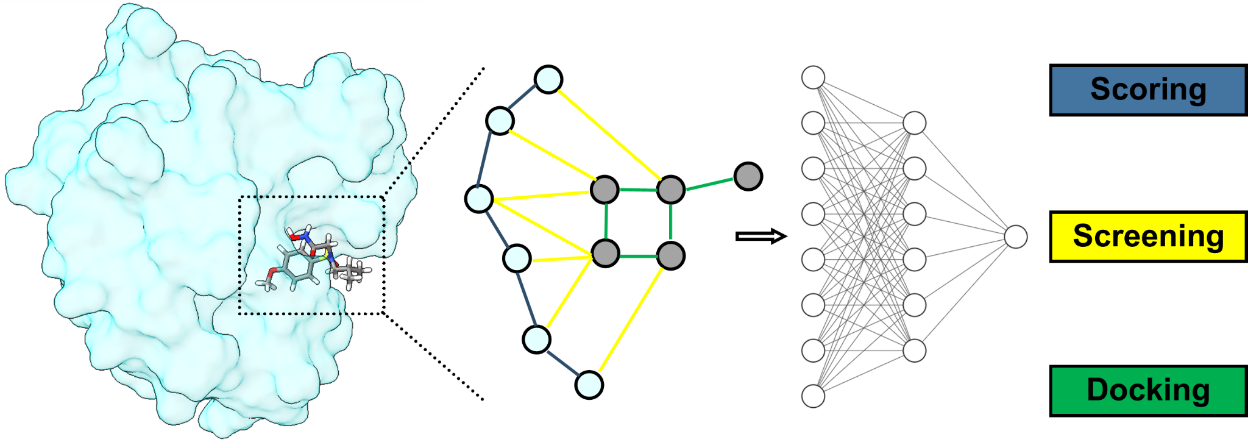
Identificación computacional de compuestos con potencial farmacológico.
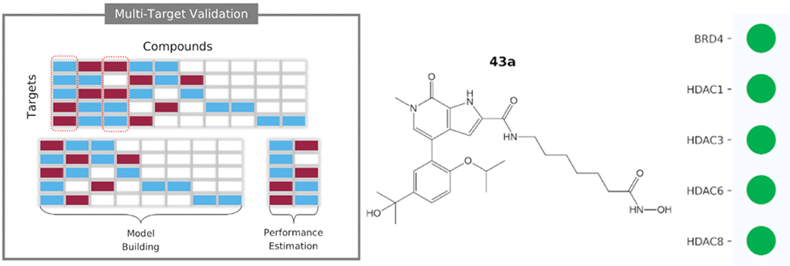
El paradigma central del descubrimiento de fármacos involucra la identificación y diseño de moléculas capaces de modular macromoléculas biológicas clave para el desarrollo de una enfermedad. En nuestro grupo de investigación se desarrollan y aplican modelos predictivos que nos permiten anticipar la capacidad que tendrán los compuestos de modular dichos blancos biológicos. Estos proyectos se realizan en colaboración con distintos grupos con las capacidades de evaluar experimentalmente dichas predicciones. Actualmente se trabaja en tres frentes principales, la búsqueda de nuevos compuestos con capacidad antibacteriana para combatir la resistencia a antimicrobianos (Laboratorio de Microbiología, Instituto de Química), la búsqueda de compuestos con capacidad de modular blancos biológicos validados para el tratamiento del cáncer (Grupo de Diseño de Fármacos Asistido por Computadora, Facultad de Química), y la búsqueda de nuevos antivirales (Unidad de Biotecnología, Centro de Investigación Científica de Yucatán).
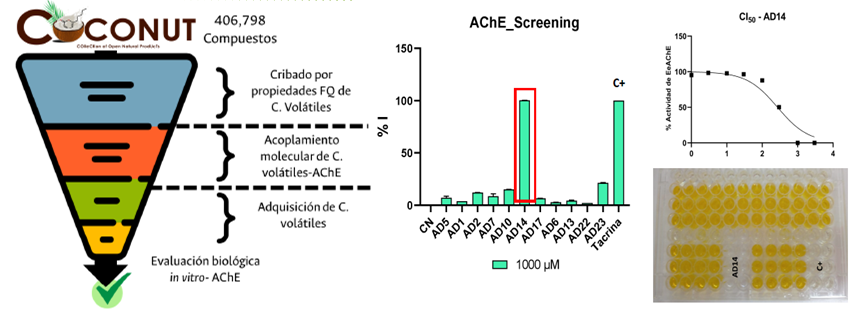
Identificación computacional de compuestos con potencial uso agrícola.
La identificación de moléculas pequeñas capaces de modular blancos biológicos específicos tiene distintas aplicaciones fuera del diseño de fármacos, ya que muchos otros procesos biológicos están mediados por las interacciones que se presentan entre estos tipos de moléculas. Los modelos predictivos que se desarrollan en el grupo se aplican en áreas distintas al diseño de fármacos, tales como la búsqueda de nuevos compuestos para el control de plagas en distintos cultivos. Estos proyectos también se realizan en colaboración con distintos grupos con las capacidades de evaluar experimentalmente dichas predicciones. Actualmente se trabaja en la búsqueda de nuevos plaguicidas para el cultivo del plátano (Grupo de Investigación en Macromoléculas, Universidad Nacional de Colombia).
Cursos de licenciatura impartidos en la Facultad de Química, UNAM:
Introducción a la quimioinformática.
Cursos de licenciatura impartidos en la Facultad de Química, UADY:
Introducción a la quimioinformática.
Cursos de maestría en el posgrado en Ciencias Químicas, UNAM:
Python para Químicos
Se reciben alumnos para realizar tesis de Licenciatura y Posgrado.
Miembro del Sistema Nacional de Investigadores (SNI – CONAHCyT), Nivel 1.
Artículo más citado 2020-2021. Wiley, Molecular Informatics.
Mención Honorífica en defensa de tesis doctoral, UNAM 2021.
Mención Honorífica en la competición de carteles del 6th Latin American Protein Society Meeting. 2019.
Mención Honorífica en defensa de tesis de maestría. UNAM 2017.
Mención Honorífica en defensa de tesis de licenciatura. UNAM 2014.
Prado-Romero, D.L.; Saldívar-González, F.I.; López-Mata, I.; Laurel-García, P.A.; Durán-Vargas, A; García-Hernández, E.; Sánchez-Cruz, N.; Medina-Franco, J.L.* De Novo Design of Inhibitors of DNA Methyltransferase 1: A Critical Comparison of Ligand- and Structure-Based Approaches. Biomolecules 2024, 14(7), 775. https://doi.org/10.3390/biom14070775.
Hernández-Garrido CA, Sánchez-Cruz N. Experimental Uncertainty in Training Data for Protein-Ligand Binding Affinity Prediction Models. Artif Intell Life Sci. 2023, 4: 100087. https://doi.org/10.1016/j.ailsci.2023.100087
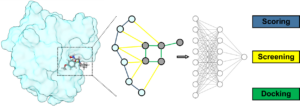
Sánchez-Cruz N. Deep graph learning in molecular docking: Advances and opportunities. Artif Intell Life Sci. 2023, 3: 100062. https://doi.org/10.1016/j.ailsci.2023.100062
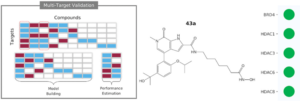
Sánchez-Cruz N, Medina-Franco JL. Epigenetic Target Fishing with Accurate Machine Learning Models. J Med Chem. 2021, 64 (12): 8208. https://doi.org/10.1021/acs.jmedchem.1c00020.
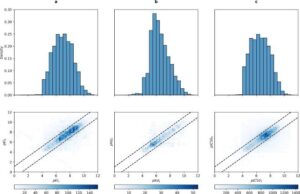
Sánchez-Cruz N, Medina-Franco JL, Mestres J, Barril, X. Extended Connectivity Interaction Features: Improving Binding Affinity Prediction through Chemical Description. Bioinformatics 2021, 37 (10), 1376. https://doi.org/10.1093/bioinformatics/btaa982.